Search
The search bar is an important mechanism for discovering data assets in DataHub. From the search bar, you can find Datasets, Columns, Dashboards, Charts, Data Pipelines, and more. Simply type in a term and press 'enter'.

Advanced queries and the filter sidebar helps fine tuning queries. For programmatic users Datahub provides a GraphQL API as well.
Search Setup, Prerequisites, and Permissions
Search is available for all users. Although Search works out of the box, the more relevant data you ingest, the better the results are.
Using Search
Searching is as easy as typing in relevant business terms and pressing 'enter' to view matching data assets.
By default, search terms will match against different aspects of a data assets. This includes asset names, descriptions, tags, terms, owners, and even specific attributes like the names of columns in a table.
Search Operators
The default boolean logic used to interpret text in a query string is AND. For example, a query of information about orders is interpreted as information AND about AND orders.
Filters
The filters sidebar sits on the left hand side of search results, and lets users find assets by drilling down. You can quickly filter by Data Platform (e.g. Snowflake), Tags, Glossary Terms, Domain, Owners, and more with a single click.
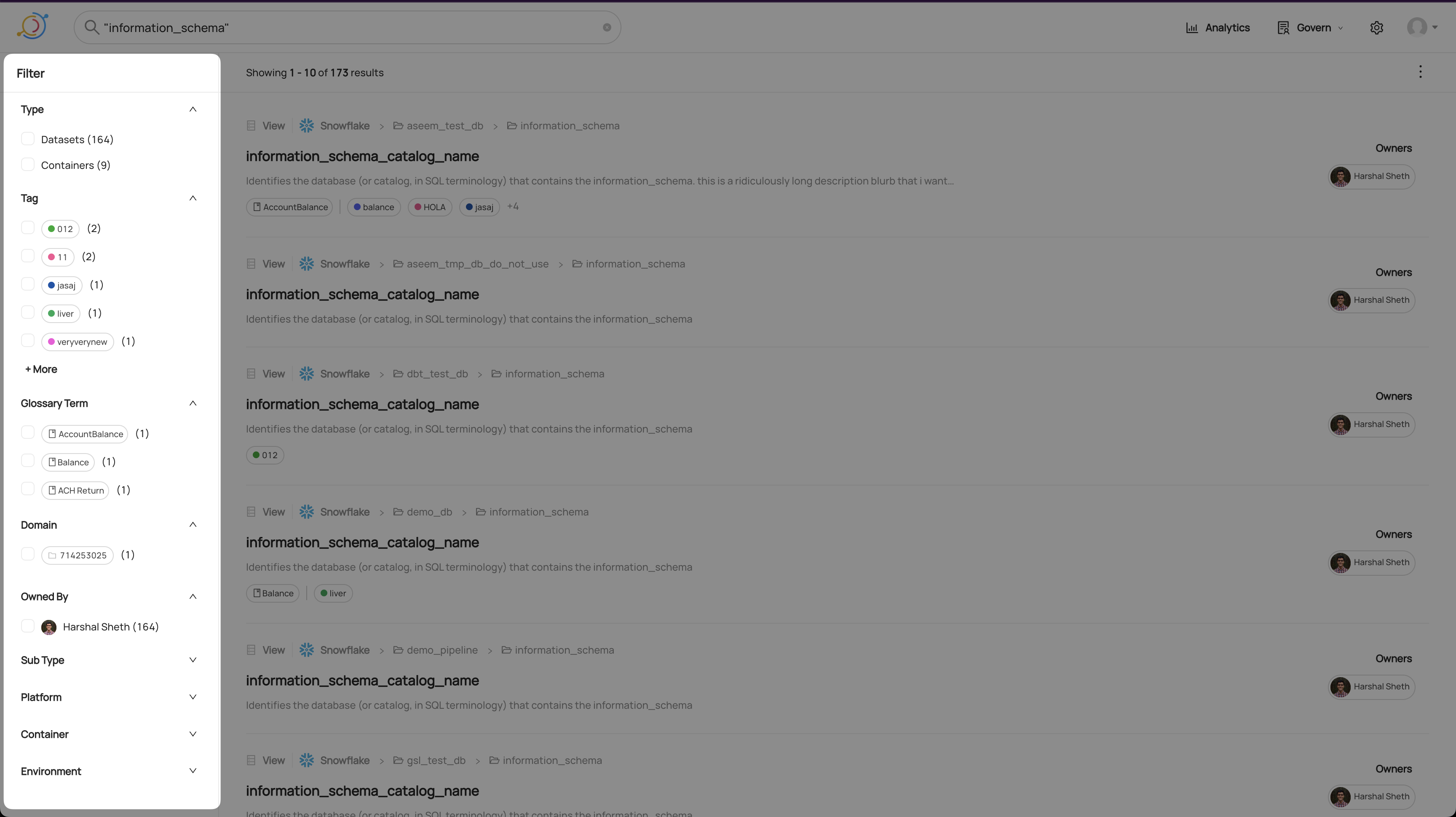
Advanced Filters
Using the Advanced Filter view, you can apply more complex filters. To get there, click 'Advanced' in the top right of the filter panel:
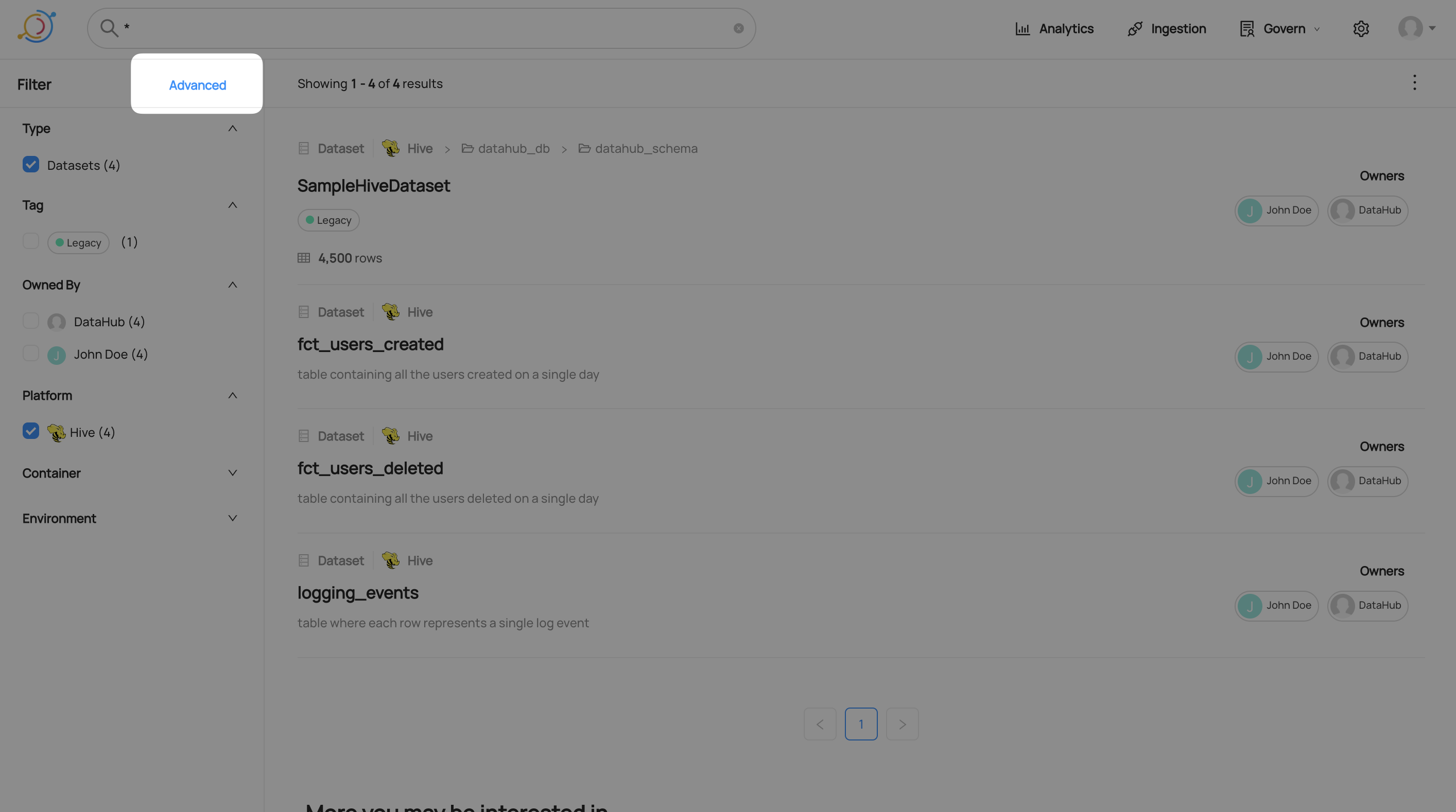
Adding an Advanced Filter
Currently, Advanced Filters support filtering by Column Name, Container, Domain, Description (entity or column level), Tag (entity or column level), Glossary Term (entity or column level), Owner, Entity Type, Subtype, Environment and soft-deleted status.
To add a new filter, click the add filter menu, choose a filter type, and then fill in the values you want to filter by.
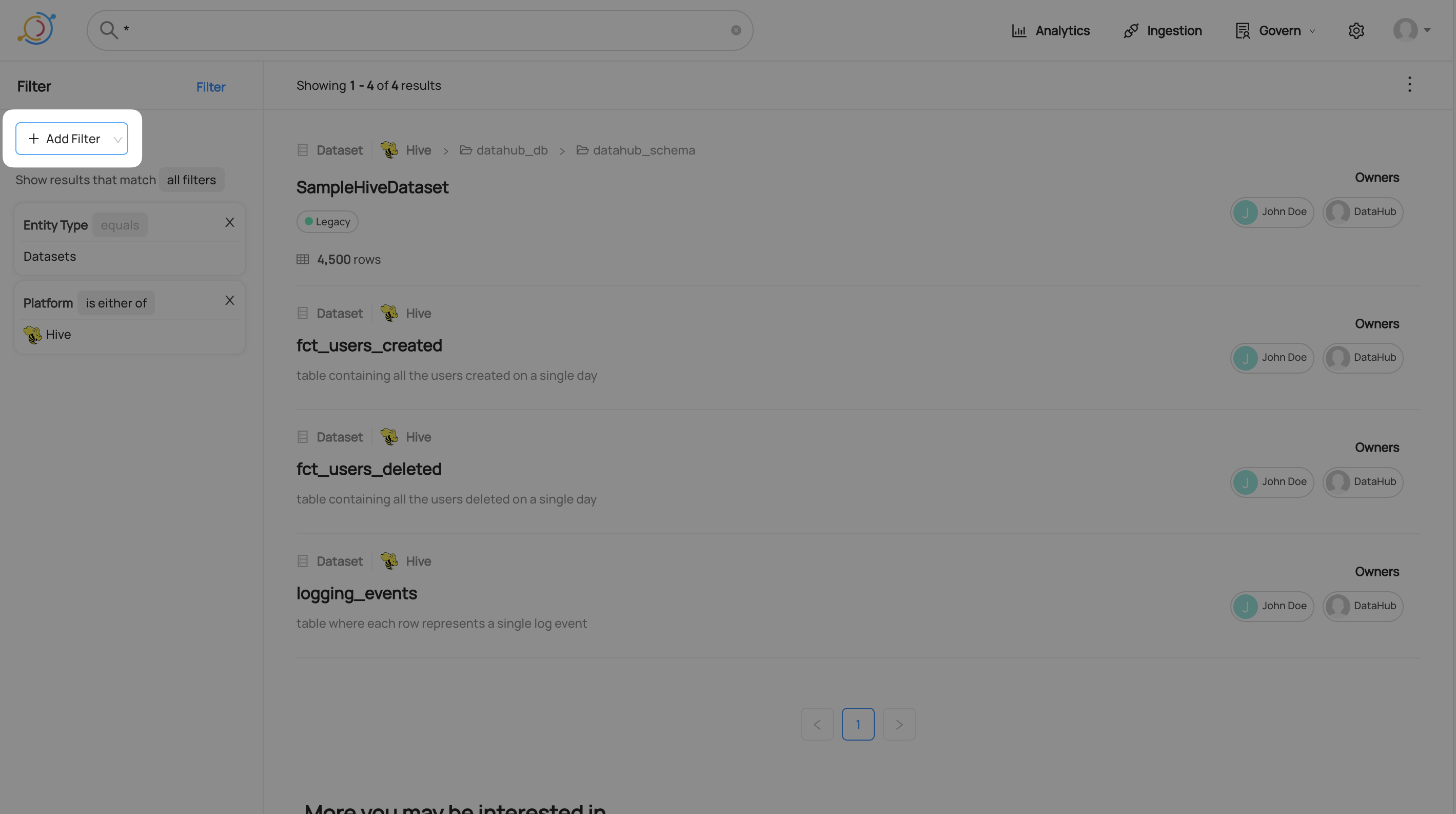
Matching Any Advanced Filter
By default, all filters must be matched in order for a result to appear. For example, if you add a tag filter and a platform filter, all results will have the tag and the platform. You can set the results to match any filter instead. Click on all filters and select any filter from the drop-down menu.
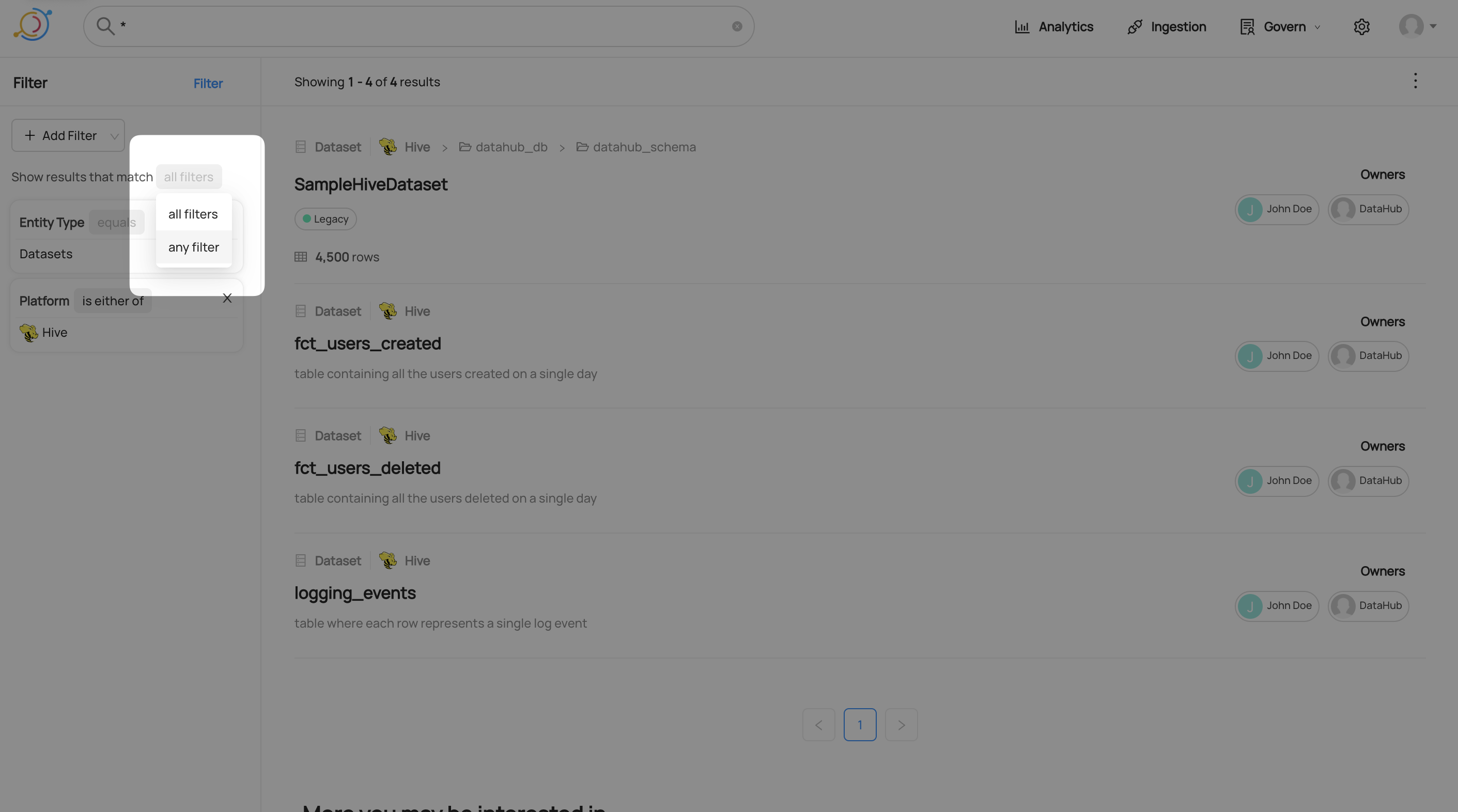
Negating An Advanced Filter
After creating a filter, you can choose whether results should or should not match it. Change this by clicking the operation in the top right of the filter and selecting the negated operation.
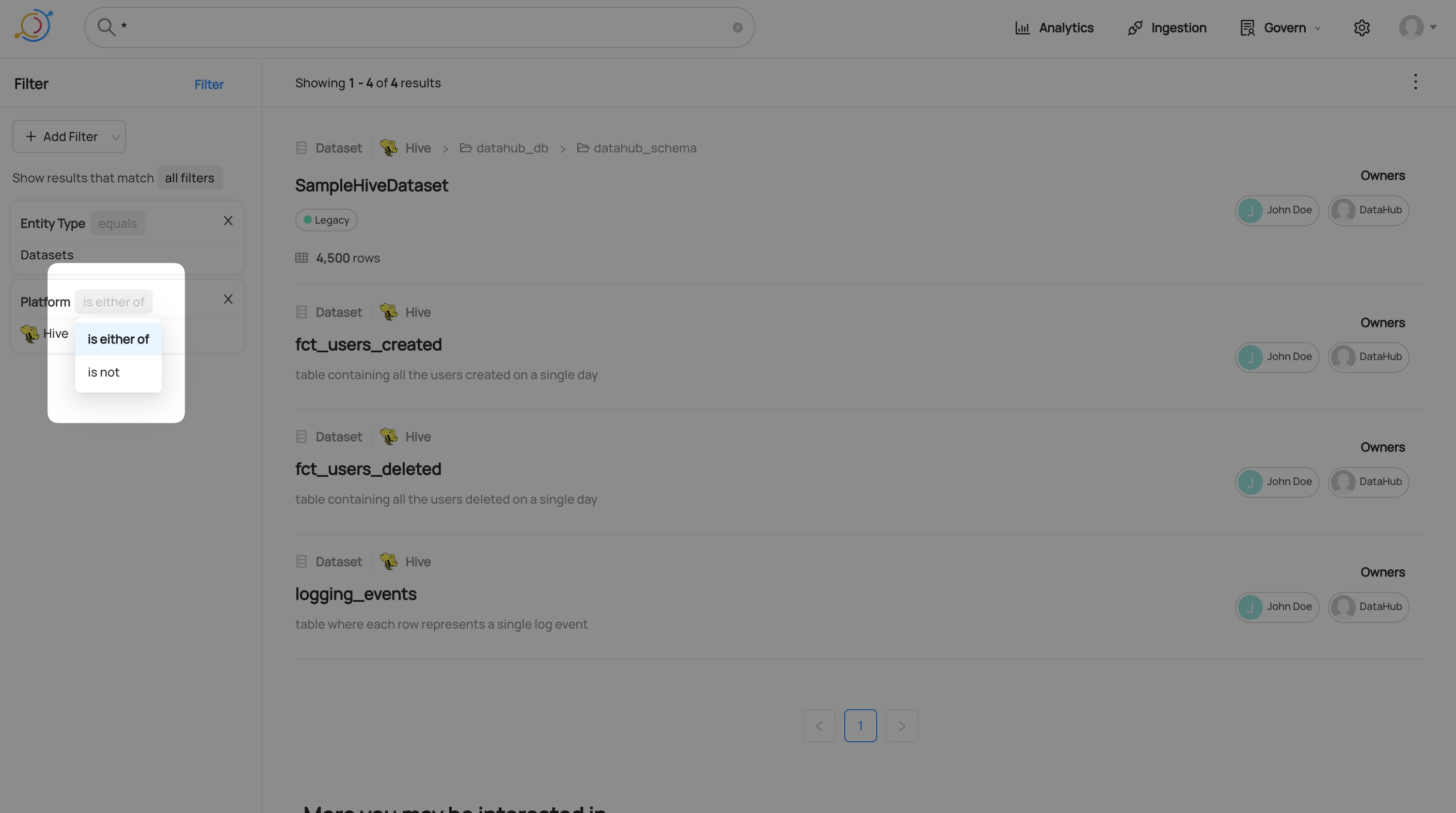
Results
Search results appear ranked by their relevance. In self-hosted DataHub ranking is based on how closely the query matched textual fields of an asset and its metadata. In DataHub Cloud, ranking is based on a combination of textual relevance, usage (queries / views), and change frequency.
With better metadata comes better results. Learn more about ingestion technical metadata in the metadata ingestion guide.
Advanced queries
The search bar supports advanced queries with pattern matching, logical expressions and filtering by specific field matches.
The following are use cases with example search phrases. Additionally, an example link is provided for our demo instance. These examples are non exhaustive and using Datasets as a reference.
If you want to:
Exact match on term or phrase
"pet profile"Sample resultspet profileSample results- Enclosing one or more terms with double quotes will enforce exact matching on these terms, preventing further tokenization.
Exclude terms
logging -snowflakeSample results- Results can be excluded by term using
-to negate the term.
Term boolean logic with precedence
logging + (-snowflake | os_audit_log)Sample results()can be used to set precedence of boolean term expressions
Find a dataset with the word mask in the name:
/q name: *mask*Sample results- This will return entities with mask in the name. Names tends to be connected by other symbols, hence the wildcard symbols before and after the word.
Find a dataset with a property, encoding
/q customProperties: encoding*Sample results- Dataset Properties are indexed in ElasticSearch the manner of key=value. Hence if you know the precise key-value pair, you can search using
"key=value". However, if you only know the key, you can use wildcards to replace the value and that is what is being done here.
Find an entity with an unversioned structured property
/q structuredProperties.io_acryl_privacy_retentionTime01:60- This will return results for an unversioned structured property's qualified name
io.acryl.private.retentionTime01and value60. /q _exists_:structuredProperties.io_acryl_privacy_retentionTime01- In this example, the query will return any entity which has any value for the unversioned structured property with qualified name
io.acryl.private.retentionTime01.
Find an entity with a versioned structured property
/q structuredProperties._versioned.io_acryl_privacy_retentionTime.20240614080000.number:365- This query will return results for a versioned structured property with qualified name
io.acryl.privacy.retentionTime, version20240614080000, typenumberand value365. /q _exists_:structuredProperties._versioned.io_acryl_privacy_retentionTime.20240614080000.number- Returns results for a versioned structured property with qualified name
io.acryl.privacy.retentionTime, version20240614080000and typenumber. /q structuredProperties._versioned.io_acryl_privacy_retentionTime.\*.\*:365- Returns results for a versioned structured property with any version and type with a values of
365
Find a dataset with a column name, latitude
/q fieldPaths: latitudeSample results- fieldPaths is the name of the attribute that holds the column name in Datasets.
Find a dataset with the term latitude in the field description
/q editedFieldDescriptions: latitude OR fieldDescriptions: latitudeSample results- Datasets has 2 attributes that contains field description. fieldDescription comes from the SchemaMetadata aspect, while editedFieldDescriptions comes from the EditableSchemaMetadata aspect. EditableSchemaMetadata holds information that comes from UI edits, while SchemaMetadata holds data from ingestion of the dataset.
Find a dataset with the term logical in the dataset description
/q editedDescription: *logical* OR description: *logical*Sample results- Similar to field descriptions, dataset descriptions can be found in 2 aspects, hence the need to search 2 attributes.
Find a dataset which resides in one of the browsing folders, for instance, the hive folder
/q browsePaths: *hive*Sample results- BrowsePath is stored as a complete string, for instance
/datasets/prod/hive/SampleKafkaDataset, hence the need for wildcards on both ends of the term to return a result.
Find a dataset without the name field
/q -_exists_:nameSample results- the
-is negating the existence of the field name.
Videos
What can you do with DataHub?
GraphQL
- searchAcrossEntities
- You can try out the API on the demo instance's public GraphQL interface: here
The same GraphQL API that powers the Search UI can be used for integrations and programmatic use-cases.
# Example query - search for datasets matching the example_query_text who have the Dimension tag applied to a schema field and are from the data platform looker
query searchEntities {
search(
input: {
type: DATASET,
query: "example_query_text",
orFilters: [
{
and: [
{
field: "fieldTags",
values: ["urn:li:tag:Dimension"]
},
{
field: "platform",
values: ["urn:li:dataPlatform:looker"]
}
]
}
],
start: 0,
count: 10
}
) {
start
count
total
searchResults {
entity {
urn
type
... on Dataset {
name
platform {
name
}
}
}
}
}
}
Searching at Scale
For queries that return more than 10k entities we recommend using the scrollAcrossEntities GraphQL API:
# Example query
{
scrollAcrossEntities(input: { types: [DATASET], query: "*", count: 10}) {
nextScrollId
count
searchResults {
entity {
type
... on Dataset {
urn
type
platform {
name
}
name
}
}
}
}
}
This will return a response containing a nextScrollId value which must be used in subsequent queries to retrieve more data, i.e:
{
scrollAcrossEntities(input:
{ types: [DATASET], query: "*", count: 10,
scrollId: "eyJzb3J0IjpbMy4wLCJ1cm46bGk6ZGF0YXNldDoodXJuOmxpOmRhdGFQbGF0Zm9ybTpiaWdxdWVyeSxiaWdxdWVyeS1wdWJsaWMtZGF0YS5jb3ZpZDE5X2dlb3RhYl9tb2JpbGl0eV9pbXBhY3QucG9ydF90cmFmZmljLFBST0QpIl0sInBpdElkIjpudWxsLCJleHBpcmF0aW9uVGltZSI6MH0="}
) {
nextScrollId
count
searchResults {
entity {
type
... on Dataset {
urn
type
platform {
name
}
name
}
}
}
}
}
In order to complete scrolling through all of the results, continue to request data in batches until the nextScrollId returned is null or undefined.
DataHub Blog
Customizing Search
It is possible to completely customize search ranking, filtering, and queries using a search configuration yaml file.
This no-code solution provides the ability to extend, or replace, the Elasticsearch-based search functionality. The
only limitation is that the information used in the query/ranking/filtering must be present in the entities' document,
however this does include customProperties, tags, terms, domain, as well as many additional fields.
Additionally, multiple customizations can be applied to different query strings. A regex is applied to the search query
to determine which customized search profile to use. This means a different query/ranking/filtering can be applied to
a select all/* query or one that contains an actual query.
Search results (excluding select *) are a balance between relevancy and the scoring function. In
general, when trying to improve relevancy, focus on changing the query in the boolQuery section and rely on the
functionScore for surfacing the importance in the case of a relevancy tie. Consider the scenario
where a dataset named orders exists in multiple places. The relevancy between the dataset with the name orders and
the term orders is the same, however one location may be more important and thus the function score preferred.
Note: The customized query is a pass-through to Elasticsearch and must comply with their API, syntax errors are possible. It is recommended to test the customized queries prior to production deployment and knowledge of the Elasticsearch query language is required.
Enable Custom Search
The following environment variables on GMS control whether a search configuration is enabled and the location of the configuration file.
Enable Custom Search:
ELASTICSEARCH_QUERY_CUSTOM_CONFIG_ENABLED=true
Custom Search File Location:
ELASTICSEARCH_QUERY_CUSTOM_CONFIG_FILE=search_config.yml
The location of the configuration file can be on the Java classpath or the local filesystem. A default configuration
file is included with the GMS jar with the name search_config.yml.
Search Configuration
The search configuration yaml contains a simple list of configuration profiles selected using the queryRegex. If a
single profile is desired, a catch-all regex of .* can be used.
The list of search configurations can be grouped into 4 general sections.
queryRegex- Responsible for selecting the search customization based on the regex matching the search query string. The first match is applied.- Built-in query booleans - There are 3 built-in queries which can be individually enabled/disabled. These include
the
simple query string[1],match phrase prefix[2], andexact match[3] queries, enabled with the following booleans respectively [simpleQuery,prefixMatchQuery,exactMatchQuery] boolQuery- The base Elasticsearchboolean query[4]. If enabled in #2 above, those queries will appear in theshouldsection of theboolean query[4].functionScore- The Elasticsearchfunction score[5] section of the overall query.
Examples
These examples assume a match-all queryRegex of .* so that it would impact any search query for simplicity.
Example 1: Ranking By Tags/Terms
Boost entities with tags of primary or gold and an example glossary term's uuid.
queryConfigurations:
- queryRegex: .*
simpleQuery: true
prefixMatchQuery: true
exactMatchQuery: true
functionScore:
functions:
- filter:
terms:
tags.keyword:
- urn:li:tag:primary
- urn:li:tag:gold
weight: 3.0
- filter:
terms:
glossaryTerms.keyword:
- urn:li:glossaryTerm:9afa9a59-93b2-47cb-9094-aa342eec24ad
weight: 3.0
score_mode: multiply
boost_mode: multiply
Similar example to boost with primary AND gold instead of the previous OR condition.
queryConfigurations:
- queryRegex: .*
simpleQuery: true
prefixMatchQuery: true
exactMatchQuery: true
functionScore:
functions:
- filter:
bool:
filter:
- term:
tags.keyword: urn:li:tag:primary
- term:
tags.keyword: urn:li:tag:gold
weight: 3.0
score_mode: multiply
boost_mode: multiply
Example 2: Preferred Data Platform
Boost the urn:li:dataPlatform:hive platform.
queryConfigurations:
- queryRegex: .*
simpleQuery: true
prefixMatchQuery: true
exactMatchQuery: true
functionScore:
functions:
- filter:
terms:
platform.keyword:
- urn:li:dataPlatform:hive
weight: 3.0
score_mode: multiply
boost_mode: multiply
Example 3: Exclusion & Bury
This configuration extends the 3 built-in queries with a rule to exclude deprecated entities from search results
because they are not generally relevant as well as reduces the score of materialized.
queryConfigurations:
- queryRegex: .*
simpleQuery: true
prefixMatchQuery: true
exactMatchQuery: true
boolQuery:
must_not:
term:
deprecated:
value: true
functionScore:
functions:
- filter:
term:
materialized:
value: true
weight: 0.5
score_mode: multiply
boost_mode: multiply
Example 4: Entity Ranking
Alter the ranking of entities. For example, chart vs dashboard, you may want the dashboard to appear above charts. This can be done using the following function score and leverages a prefix match on the entity type of the URN. Depending on the entity the weight may have to be adjusted based on your data and the entities involved since often multiple field matches may shift weight towards one entity vs another.
queryConfigurations:
- queryRegex: .*
simpleQuery: true
prefixMatchQuery: true
exactMatchQuery: true
functionScore:
functions:
- filter:
prefix:
urn:
value: 'urn:li:dashboard:'
weight: 1.5
score_mode: multiply
boost_mode: multiply
Search Autocomplete Configuration
Similar to the options provided in the previous section for search configuration, there are autocomplete specific options which can be configured.
Note: The scoring functions defined in the previous section are inherited for autocomplete by default, unless overrides are provided in the autocomplete section.
For the most part the configuration options are identical to the search customization options in the previous
section, however they are located under autocompleteConfigurations in the yaml configuration file.
queryRegex- Responsible for selecting the search customization based on the regex matching the search query string. The first match is applied.- The following boolean enables/disables the function score inheritance from the normal search configuration: [
inheritFunctionScore] This flag will automatically be set tofalsewhen thefunctionScoresection is provided. If set tofalsewith nofunctionScoreprovided, the default Elasticsearch_scoreis used. - Built-in query booleans - There is 1 built-in query which can be enabled/disabled. These include
the
default autocomplete queryquery, enabled with the following booleans respectively [defaultQuery] boolQuery- The base Elasticsearchboolean query[4]. If enabled in #2 above, those queries will appear in theshouldsection of theboolean query[4].functionScore- The Elasticsearchfunction score[5] section of the overall query.
Examples
These examples assume a match-all queryRegex of .* so that it would impact any search query for simplicity. Also
note that the queryRegex is applied individually for searchConfigurations and autocompleteConfigurations and they
do not have to be identical.
Example 1: Exclude deprecated entities from autocomplete
autocompleteConfigurations:
- queryRegex: .*
defaultQuery: true
boolQuery:
must:
- term:
deprecated: 'false'
Example 2: Override scoring for autocomplete
autocompleteConfigurations:
- queryRegex: .*
defaultQuery: true
functionScore:
functions:
- filter:
term:
materialized:
value: true
weight: 1.1
- filter:
term:
deprecated:
value: false
weight: 0.5
score_mode: avg
boost_mode: multiply
FAQ and Troubleshooting
How are the results ordered?
The order of the search results is based on the weight what Datahub gives them based on our search algorithm. The current algorithm in OSS DataHub is based on a text-match score from Elasticsearch.
Where to find more information?
The sample queries here are non exhaustive. The link here shows the current list of indexed fields for each entity inside Datahub. Click on the fields inside each entity and see which field has the tag Searchable.
However, it does not tell you the specific attribute name to use for specialized searches. One way to do so is to inspect the ElasticSearch indices, for example:
curl http://localhost:9200/_cat/indices returns all the ES indices in the ElasticSearch container.
yellow open chartindex_v2_1643510690325 bQO_RSiCSUiKJYsmJClsew 1 1 2 0 8.5kb 8.5kb
yellow open mlmodelgroupindex_v2_1643510678529 OjIy0wb7RyKqLz3uTENRHQ 1 1 0 0 208b 208b
yellow open dataprocessindex_v2_1643510676831 2w-IHpuiTUCs6e6gumpYHA 1 1 0 0 208b 208b
yellow open corpgroupindex_v2_1643510673894 O7myCFlqQWKNtgsldzBS6g 1 1 3 0 16.8kb 16.8kb
yellow open corpuserindex_v2_1643510672335 0rIe_uIQTjme5Wy61MFbaw 1 1 6 2 32.4kb 32.4kb
yellow open datasetindex_v2_1643510688970 bjBfUEswSoSqPi3BP4iqjw 1 1 15 0 29.2kb 29.2kb
yellow open dataflowindex_v2_1643510681607 N8CMlRFvQ42rnYMVDaQJ2g 1 1 1 0 10.2kb 10.2kb
yellow open dataset_datasetusagestatisticsaspect_v1_1643510694706 kdqvqMYLRWq1oZt1pcAsXQ 1 1 4 0 8.9kb 8.9kb
yellow open .ds-datahub_usage_event-000003 YMVcU8sHTFilUwyI4CWJJg 1 1 186 0 203.9kb 203.9kb
yellow open datajob_datahubingestioncheckpointaspect_v1 nTXJf7C1Q3GoaIJ71gONxw 1 1 0 0 208b 208b
yellow open .ds-datahub_usage_event-000004 XRFwisRPSJuSr6UVmmsCsg 1 1 196 0 165.5kb 165.5kb
yellow open .ds-datahub_usage_event-000005 d0O6l5wIRLOyG6iIfAISGw 1 1 77 0 108.1kb 108.1kb
yellow open dataplatformindex_v2_1643510671426 _4SIIhfAT8yq_WROufunXA 1 1 0 0 208b 208b
yellow open mlmodeldeploymentindex_v2_1643510670629 n81eJIypSp2Qx-fpjZHgRw 1 1 0 0 208b 208b
yellow open .ds-datahub_usage_event-000006 oyrWKndjQ-a8Rt1IMD9aSA 1 1 143 0 127.1kb 127.1kb
yellow open mlfeaturetableindex_v2_1643510677164 iEXPt637S1OcilXpxPNYHw 1 1 5 0 8.9kb 8.9kb
yellow open .ds-datahub_usage_event-000001 S9EnGj64TEW8O3sLUb9I2Q 1 1 257 0 163.9kb 163.9kb
yellow open .ds-datahub_usage_event-000002 2xJyvKG_RYGwJOG9yq8pJw 1 1 44 0 155.4kb 155.4kb
yellow open dataset_datasetprofileaspect_v1_1643510693373 uahwTHGRRAC7w1c2VqVy8g 1 1 31 0 18.9kb 18.9kb
yellow open mlprimarykeyindex_v2_1643510687579 MUcmT8ASSASzEpLL98vrWg 1 1 7 0 9.5kb 9.5kb
yellow open glossarytermindex_v2_1643510686127 cQL8Pg6uQeKfMly9GPhgFQ 1 1 3 0 10kb 10kb
yellow open datajob_datahubingestionrunsummaryaspect_v1 rk22mIsDQ02-52MpWLm1DA 1 1 0 0 208b 208b
yellow open mlmodelindex_v2_1643510675399 gk-WSTVjRZmkDU5ggeFSqg 1 1 1 0 10.3kb 10.3kb
yellow open dashboardindex_v2_1643510691686 PQjSaGhTRqWW6zYjcqXo6Q 1 1 1 0 8.7kb 8.7kb
yellow open datahubpolicyindex_v2_1643510671774 ZyTrYx3-Q1e-7dYq1kn5Gg 1 1 0 0 208b 208b
yellow open datajobindex_v2_1643510682977 K-rbEyjBS6ew5uOQQS4sPw 1 1 2 0 11.3kb 11.3kb
yellow open datahubretentionindex_v2 8XrQTPwRTX278mx1SrNwZA 1 1 0 0 208b 208b
yellow open glossarynodeindex_v2_1643510678826 Y3_bCz0YR2KPwCrrVngDdA 1 1 1 0 7.4kb 7.4kb
yellow open system_metadata_service_v1 36spEDbDTdKgVlSjE8t-Jw 1 1 387 8 63.2kb 63.2kb
yellow open schemafieldindex_v2_1643510684410 tZ1gC3haTReRLmpCxirVxQ 1 1 0 0 208b 208b
yellow open mlfeatureindex_v2_1643510680246 aQO5HF0mT62Znn-oIWBC8A 1 1 20 0 17.4kb 17.4kb
yellow open tagindex_v2_1643510684785 PfnUdCUORY2fnF3I3W7HwA 1 1 3 1 18.6kb 18.6kb
The index name will vary from instance to instance. Indexed information about Datasets can be found in:
curl http://localhost:9200/datasetindex_v2_1643510688970/_search?=pretty
example information of a dataset:
{
"_index" : "datasetindex_v2_1643510688970",
"_type" : "_doc",
"_id" : "urn%3Ali%3Adataset%3A%28urn%3Ali%3AdataPlatform%3Akafka%2CSampleKafkaDataset%2CPROD%29",
"_score" : 1.0,
"_source" : {
"urn" : "urn:li:dataset:(urn:li:dataPlatform:kafka,SampleKafkaDataset,PROD)",
"name" : "SampleKafkaDataset",
"browsePaths" : [
"/prod/kafka/SampleKafkaDataset"
],
"origin" : "PROD",
"customProperties" : [
"prop2=pikachu",
"prop1=fakeprop"
],
"hasDescription" : false,
"hasOwners" : true,
"owners" : [
"urn:li:corpuser:jdoe",
"urn:li:corpuser:datahub"
],
"fieldPaths" : [
"[version=2.0].[type=boolean].field_foo_2",
"[version=2.0].[type=boolean].field_bar",
"[version=2.0].[key=True].[type=int].id"
],
"fieldGlossaryTerms" : [ ],
"fieldDescriptions" : [
"Foo field description",
"Bar field description",
"Id specifying which partition the message should go to"
],
"fieldTags" : [
"urn:li:tag:NeedsDocumentation"
],
"platform" : "urn:li:dataPlatform:kafka"
}
},
