Metadata Ingestion Architecture
DataHub supports an extremely flexible ingestion architecture that can support push, pull, asynchronous and synchronous models. The figure below describes all the options possible for connecting your favorite system to DataHub.
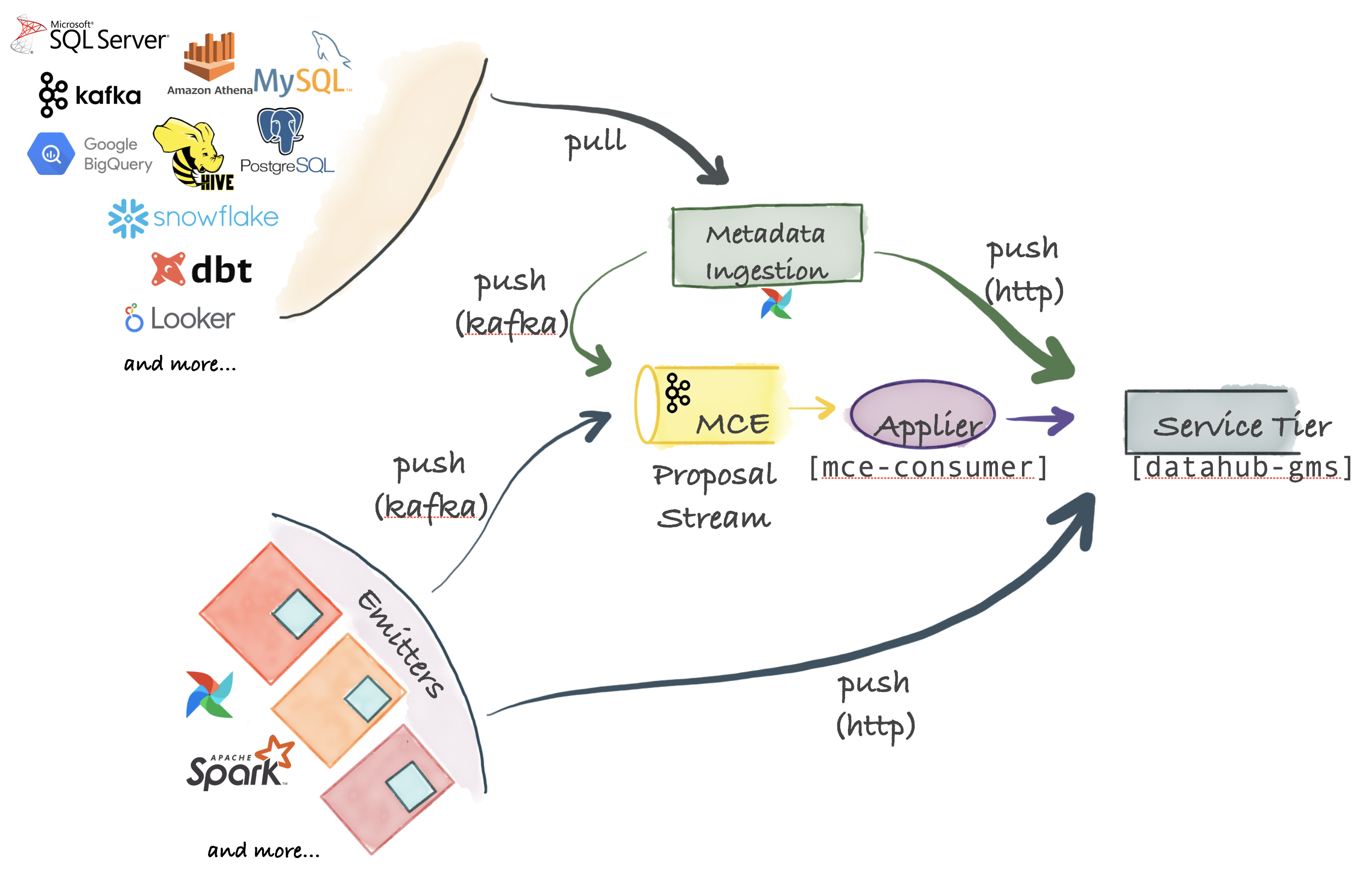
Metadata Change Proposal: The Center Piece
The center piece for ingestion are Metadata Change Proposals which represent requests to make a metadata change to an organization's Metadata Graph. Metadata Change Proposals can be sent over Kafka, for highly scalable async publishing from source systems. They can also be sent directly to the HTTP endpoint exposed by the DataHub service tier to get synchronous success / failure responses.
Pull-based Integration
DataHub ships with a Python based metadata-ingestion system that can connect to different sources to pull metadata from them. This metadata is then pushed via Kafka or HTTP to the DataHub storage tier. Metadata ingestion pipelines can be integrated with Airflow to set up scheduled ingestion or capture lineage. If you don't find a source already supported, it is very easy to write your own.
Push-based Integration
As long as you can emit a Metadata Change Proposal (MCP) event to Kafka or make a REST call over HTTP, you can integrate any system with DataHub. For convenience, DataHub also provides simple Python emitters for you to integrate into your systems to emit metadata changes (MCP-s) at the point of origin.
Internal Components
Applying Metadata Change Proposals to DataHub Metadata Service (mce-consumer-job)
DataHub comes with a Spring job, mce-consumer-job, which consumes the Metadata Change Proposals and writes them into the DataHub Metadata Service (datahub-gms) using the /ingest endpoint.