DataHub Architecture Overview
DataHub is a 3rd generation data catalog that enables Data Discovery, Collaboration, Governance, and end-to-end Observability that is built for the Modern Data Stack. DataHub employs a model-first philosophy, with a focus on unlocking interoperability between disparate tools & systems.
The figures below describe the high-level architecture of DataHub.
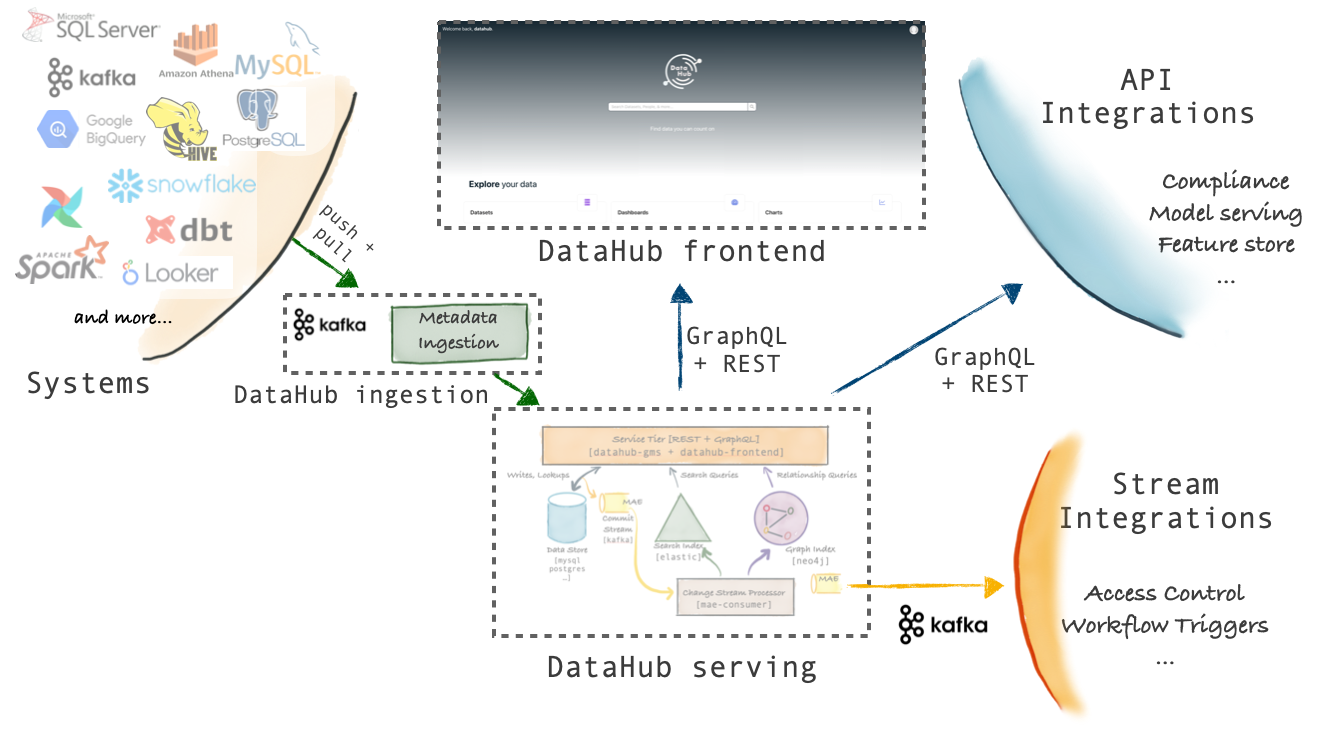
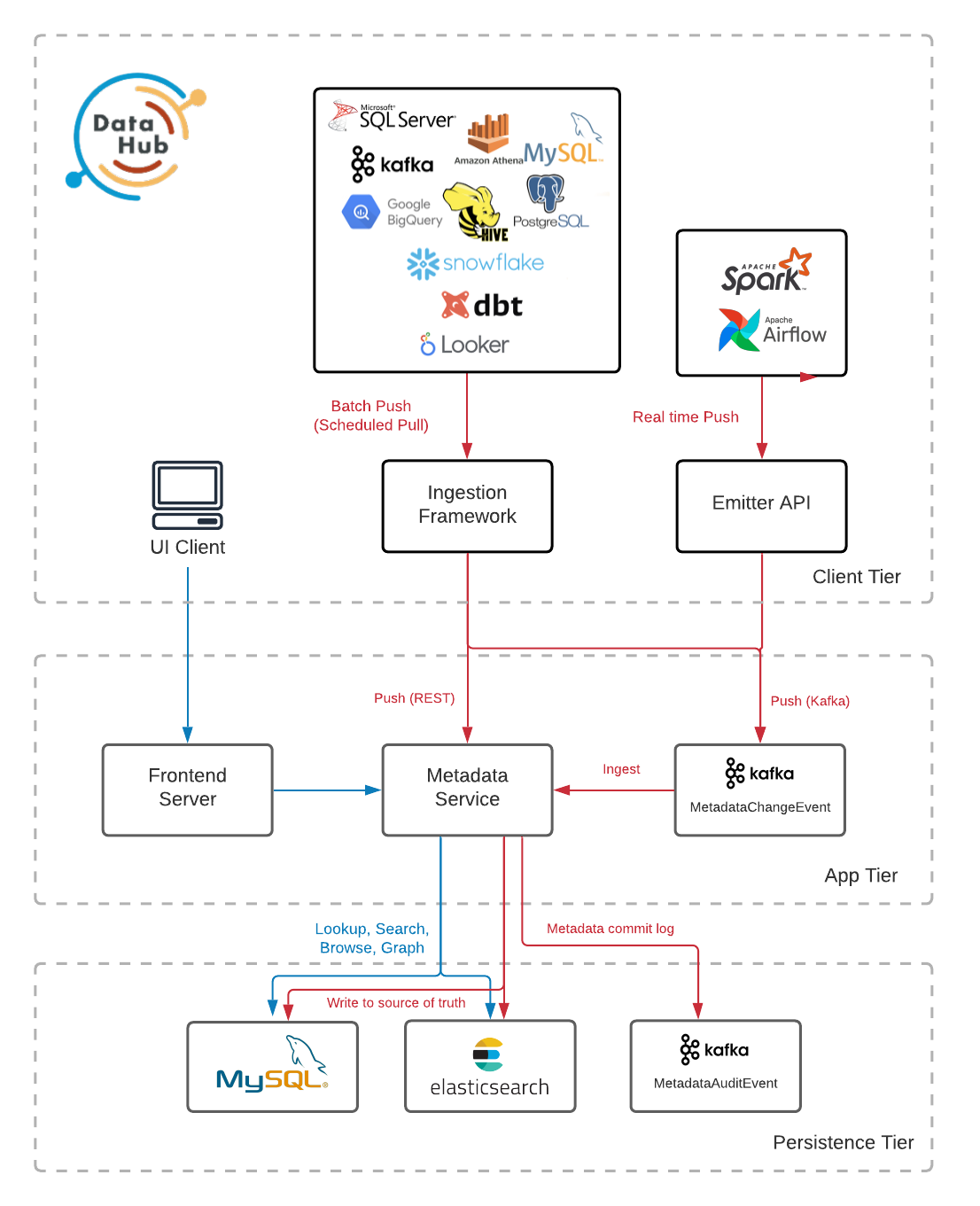
For a more detailed look at the components that make up the Architecture, check out Components.
Architecture Highlights
There are three main highlights of DataHub's architecture.
Schema-first approach to Metadata Modeling
DataHub's metadata model is described using a serialization agnostic language. Both REST as well as GraphQL API-s are supported. In addition, DataHub supports an AVRO-based API over Kafka to communicate metadata changes and subscribe to them. Our roadmap includes a milestone to support no-code metadata model edits very soon, which will allow for even more ease of use, while retaining all the benefits of a typed API. Read about metadata modeling at metadata modeling.
Stream-based Real-time Metadata Management Platform
DataHub's metadata infrastructure is stream-oriented, which allows for changes in metadata to be communicated and reflected within the platform within seconds. You can also subscribe to changes happening in DataHub's metadata, allowing you to build real-time metadata-driven systems. For example, you can build an access-control system that can observe a previously world-readable dataset adding a new schema field which contains PII, and locks down that dataset for access control reviews.
Federated Metadata Serving
DataHub comes with a single metadata service (gms) as part of the open source repository. However, it also supports federated metadata services which can be owned and operated by different teams –– in fact, that is how LinkedIn runs DataHub internally. The federated services communicate with the central search index and graph using Kafka, to support global search and discovery while still enabling decoupled ownership of metadata. This kind of architecture is very amenable for companies who are implementing data mesh.